

August 13, 2024
In the evolving landscape of AI, Large Language Models (LLMs) have significantly advanced natural language processing. However, despite their progress, these models often struggle with complex, multi-step tasks in interactive environments like web navigation. Traditional training methods relying on static datasets have proven inadequate for the dynamic and unpredictable nature of real-world interactions.
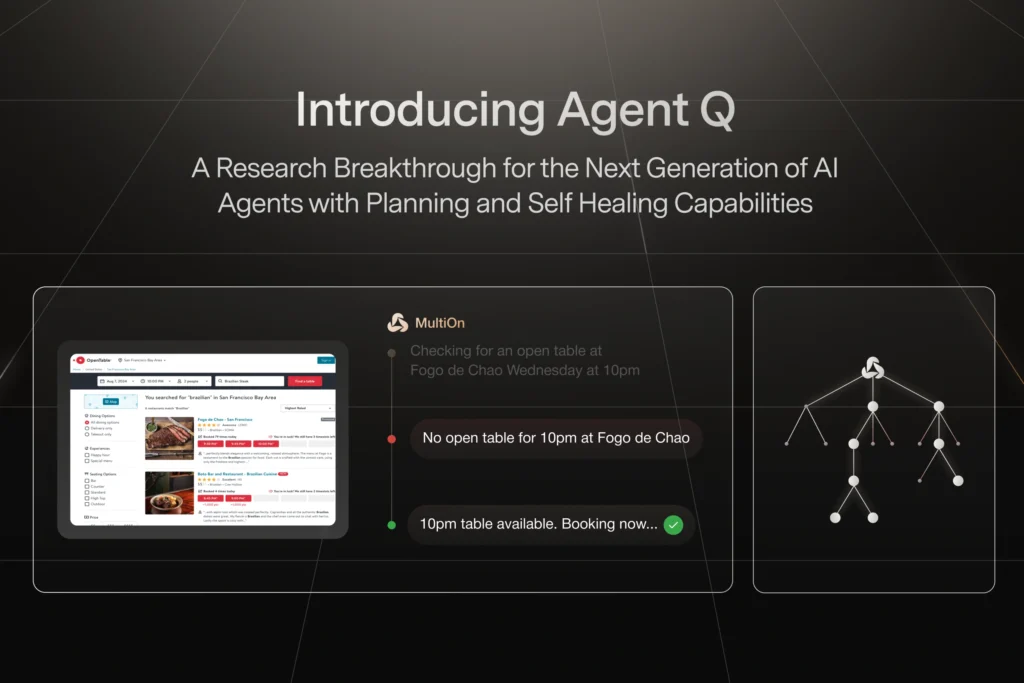
Introducing Agent Q
Agent Q represents a significant breakthrough in the development of autonomous web agents. Developed by MultiOn, Agent Q combines advanced techniques such as guided search, AI self-critique, and reinforcement learning to create a next-generation AI capable of planning and self-healing. This innovative approach addresses the shortcomings of existing LLM training methodologies, particularly in tasks requiring intricate decision-making and adaptive learning.
The Limitations of Current Methods
Current methods, such as supervised fine-tuning using expert demonstrations, often fail in multi-step tasks due to compounding errors and limited exploration data. These approaches typically result in sub-optimal policies, particularly in dynamic environments where the ability to adapt and learn from mistakes is crucial.
Agent Q: A Detailed Breakdown
Agent Q introduces a novel framework combining multiple advanced AI techniques:
- Guided Search with Monte Carlo Tree Search (MCTS): This technique autonomously generates data by exploring a variety of actions and web pages, balancing the need for exploration and exploitation. By expanding the action space with diverse prompting and high sampling temperatures, MCTS ensures a rich collection of optimal and varied trajectories.
- AI Self-Critique: At every step, Agent Q employs AI-driven self-critique, which provides immediate feedback to refine decision-making. This feedback is essential for long-horizon tasks where traditional models struggle with sparse signals.
- Direct Preference Optimization (DPO): The DPO algorithm fine-tunes the model by constructing preference pairs from MCTS-generated data. This off-policy training method allows Agent Q to learn from both optimal and sub-optimal paths, significantly improving success rates in complex environments.
Real-World Application & Results
In a real-world test involving restaurant bookings on OpenTable, MultiOn’s Agent Q demonstrated a dramatic improvement in performance. The LLaMa-3 model, initially achieving an 18.6% success rate, saw this rate increase to 81.7% after just one day of autonomous data collection. This success rate further climbed to 95.4% with the integration of online search capabilities, underscoring the efficiency and adaptability of Agent Q.
Looking Ahead
MultiOn’s Agent Q sets a new benchmark in the realm of autonomous web agents, merging cutting-edge search techniques, AI self-critique, and reinforcement learning to overcome the limitations of current models. As these methods are refined, MultiOn is preparing for a broader release, promising significant advancements in the capabilities of autonomous AI agents.



